
こんにちは、eURO2023です!
趣味(?)でRstudioをしています。
Kaplan-Meier曲線を描く機会があったので、備忘録としてまとめておきます。
医師が統計を学ぶ上で、絶対読んだほうがよい!と思われる書籍を上げておきます。


特に、新谷先生が執筆された「今日から使える医療統計」はおすすめです!
私は第一版を持っていますが、第二版が登場したようですね。
とても読みやすく、医療統計を始める上でも、論文の中身を理解する上でも非常に参考になります。
ある程度理解できるようになった今でも、よく読み返す本です。
「医療統計の基礎のキソ」は、更にわかりやすく、
「p値とはなにか?」
という超基本的な内容から、深く掘り下げてわかりやすく伝えてくれています!
第1巻から3巻までありますが、すぐに読めますよ。
下準備(パッケージの読み込み、架空データセットの作成)
今回は架空のデータセット”X”を用いて、説明していこうと思います。
架空のデータセットもRstudioで作ることが出来るんです!
架空データセット作成のためのRプロンプトを下記に示します。順に解説しますね。
# 必要なパッケージを読み込み
library(tibble)
library(survival)
library(survminer)
# 再現性のための乱数シード設定(オプション)
set.seed(123)
# 100人分の架空データを作成
n <- 100
X <- tibble(
drug_A = sample(0:1, n, replace = TRUE), # drug_Aを不使用(0) / 使用(1)
survival = sample(0:1, n, replace = TRUE), # 生存(0) / 死亡(1)
survival_month = sample(1:60, n, replace = TRUE), # 1〜60ヶ月
age = sample(40:90, n, replace = TRUE), # 40〜90歳
sex = sample(0:1, n, replace = TRUE), # 男性(0) / 女性(1)
BMI = round(runif(n, 18, 35), 1), # 18〜35の範囲でランダム
Hb = round(runif(n, 8, 16), 1), # 8〜16の範囲でランダム
PS = sample(0:4, n, replace = TRUE) # 0〜4の整数
)
# データの確認
X
# CSVとして保存したい場合(オプション)
write.csv(X, "synthetic_patient_data.csv", row.names = FALSE)必要なパッケージのインストール、読み込み
# まず今回使用するパッケージをインストールおよび出力しましょう。
# 必要なパッケージを読み込み
library(tibble)
library(survival)
library(survminer)“tibble”はRstudioを用いてデータ解析する場合にほぼ欠かせない“tidyverse”に含まれるパッケージとなります!
tidyverseは今後Rstudioでデータ解析していきたい方には必須のパッケージ群となりますので、是非インストールしてください。
ただ、私の場合、tidyverseをインストールするのにかなり苦労しました…
以前の記事でも書いたので、参考にしてください。

“survival”パッケージは、生存分析の計算を担当するパッケージです。
主な機能として、
survfit() → Kaplan-Meier生存曲線の計算
coxph() → Cox比例ハザード回帰
survreg() → ロジスティック回帰のようなパラメトリック生存モデル
Surv() → 生存時間データの扱い
などがあります。パッケージのインストールは、下記コマンドで可能です。
install.packages("survival")“survminer”パッケージは、生存分析の結果を「きれいに可視化」するためのパッケージです。
主な機能として、
ggsurvplot() → Kaplan-Meier曲線の美しいプロット
ggforest() → Cox回帰のハザード比をプロット
pairwise_survdiff() → 生存曲線のペアワイズ比較
などがあります。パッケージのインストールは、下記コマンドで可能です。
install.packages("survminer")参考になる本

また、少し難しい内容ですが、ExcelやCSVデータの整理の仕方、データ記述に関するtipsが詳しくまとめられている本になります。特にRを”Rstudio”をプラットフォームとして使っていく場合には、持っておいて損はないと思います。
乱数データの固定(オプション)
さて、ランダムデータの作成をしましょう。
このランダムデータを作成したあとに、CSVファイルとして保存して何度も使う場合は良いのですが、いちいち保存するのが面倒くさい場合は、同じデータが再現されるように、乱数データを固定します。
# 再現性のための乱数シード設定(オプション)
set.seed(123)この()内には、どの数字を入れても構いません。
架空データの作成
さて、架空データを作成してみましょう!
人数(n)は100名、変数として”drug_A”を使ったか否か(drug_A)、生存しているかどうか(survival)、生存期間(survival_month)、年齢(age)、性別(sex)、BMI(BMI)、ヘモグロビン値(Hb)およびPerformance status(PS)を用いることとします。
# 100人分の架空データを作成
n <- 100
X <- tibble(
drug_A = sample(0:1, n, replace = TRUE), # drug_Aを不使用(0) / 使用(1)
survival = sample(0:1, n, replace = TRUE), # 生存(0) / 死亡(1)
survival_month = sample(1:60, n, replace = TRUE), # 1〜60ヶ月
age = sample(40:90, n, replace = TRUE), # 40〜90歳
sex = sample(0:1, n, replace = TRUE), # 男性(0) / 女性(1)
BMI = round(runif(n, 18, 35), 1), # 18〜35の範囲でランダム
Hb = round(runif(n, 8, 16), 1), # 8〜16の範囲でランダム
PS = sample(0:4, n, replace = TRUE) # 0〜4の整数
)tibble()はdata.frame()の拡張版のようなものです。ChatGPT(無料版)では、以下のように説明されていました。
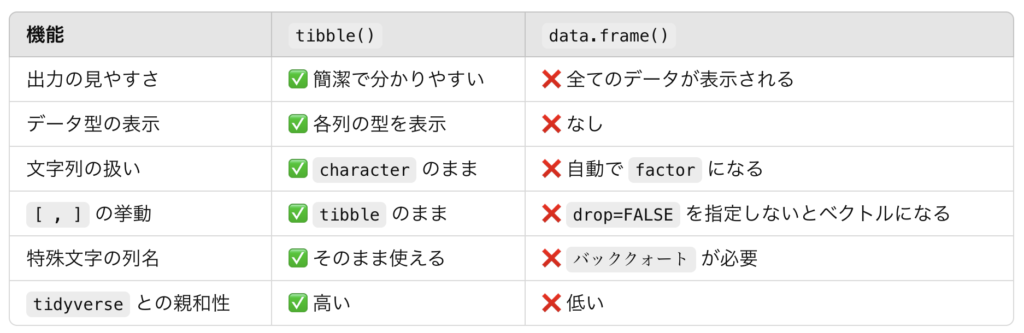
tidyverseと組み合わせて使う場合は、tibble()を用いるのが良さそうですね。
Xと入力することで、Xの中身を見ることができます。tibble()では大きいデータフレームでも一部のみしか表示されないので、Consoleを圧迫しないですみますね。
> X
# A tibble: 100 × 8
drug_A survival survival_month age sex BMI Hb PS
<int> <int> <int> <int> <int> <dbl> <dbl> <int>
1 0 0 30 66 0 23.1 10.4 1
2 0 1 30 60 0 34 14.1 2
3 0 1 52 46 1 29.7 14.8 0
4 1 0 25 65 1 25.6 11.7 0
5 0 1 16 80 0 31.9 13.8 2
6 1 1 24 59 1 18.7 8.8 1
7 1 0 54 45 0 30.6 9.8 3
8 1 0 11 89 1 23.9 15.6 4
9 0 0 48 69 0 32.1 14 2
10 0 1 20 70 1 27.1 14.6 3
# ℹ 90 more rows
# ℹ Use `print(n = ...)` to see more rowsprint(X)でも同様に表記されます。
より多くの行(rows)を表示したい場合には、下の方にも書かれているように、print(X, n=15)などのように入力してください。
ランダムに作成したXをCSVファイルに保存することもできます。
write.csv(X, "synthetic_patient_data.csv", row.names = FALSE)この”synthetic_patient_data.csv”には好きな文字を打ち込んでいただいて大丈夫です。
row.names = FALSEですが、これを入力しないと、デフォルトでrow.names = TRUEになります。
その場合、CSVファイルをRstudioに読み込んだ際、1列目に新たな列””, “1”, “2”, “3”…が新たに作成されてしまいます。
ですので、特に理由がなければrow.names = FALSEをつけておくと良いでしょう。
カプランマイヤー曲線の作成
生データでカプランマイヤー曲線を作成する場合
まず全体のRスクリプトを示します。
# サバイバルオブジェクトを作成
surv_obj <- Surv(time = X$survival_month, event = X$survival)
# 生存分析モデル (survival model) の構築
km_fit <- survfit(surv_obj ~ drug_A, data = X)
# Kaplan-Meier曲線を描画
ggsurvplot(
km_fit,
data = X,
conf.int = TRUE, # 信頼区間を表示
pval = TRUE, # Log-rank検定のp値を表示
risk.table = TRUE, # リスクテーブルを表示
legend.labs = c("No Drug A", "Drug A"), # 凡例のラベル
legend.title = "Treatment", # 凡例のタイトル
xlab = "Time (months)", # X軸ラベル
ylab = "Survival Probability", # Y軸ラベル
palette = c("#E7B800", "#2E9FDF") # 色指定
)サバイバルオブジェクトの作成
# サバイバルオブジェクトを作成
surv_obj <- Surv(time = X$survival_month, event = X$survival)Surv() は、 生存時間データ (time-to-event data) を扱うための関数です。
“生存時間”(time) と “イベントの発生有無”(event) を指定して、解析に適したデータ形式に変換してくれます。
survival パッケージ (library(survival)) に含まれています。
X$survival_month → 生存期間(例: “何ヶ月生存したか”)
X$survival → 生存状態(例: 死亡 = 1 / 生存 = 0)
つまり、「患者ごとの生存期間と、死亡したかどうかの情報を1つのオブジェクトにまとめる」
という役割を果たします。
この関数、
surv_obj <- X %>% Surv(time = survival_month, event = survival)のように、パイプ演算子をもちいてもうまくいきません。多少面倒くさいですが、X$survival_monthやX$survivalのように、その都度”データ”$”目的の列”という表記にしましょう。
($は、左にデータ、右に列を入力することで、”データ”内の”列”を意味します)
ちなみに、surv_objは新たに作成するデータセットの名前で、好きに変えていただいて構いません。
print()で、surv_objの中身を確認してみましょう。
> print(surv_obj)
[1] 30+ 30 52 25+ 16 24 54+ 11+ 48+ 20 40 3 29 36+ 52+ 44 22 49 42+ 59 20+ 11 57+
[24] 55+ 8+ 46 21 45+ 2+ 43+ 13 46+ 6 57 8 44 32 58 36 45+ 14 53 16 23+ 33 40
[47] 40 10+ 25 8 18+ 53 9+ 7 7+ 58+ 60+ 10+ 24+ 54+ 23+ 26 43 33 57+ 29 51+ 10+ 53
[70] 54+ 13 43 11 25 52+ 26+ 7+ 25 23 26 32 20+ 24+ 57+ 9+ 41 37 23+ 14+ 46 6 27+
[93] 1+ 26 42 49+ 58+ 17 29+ 26 30+ 30 52 25+ 16…と1例目から100例目まで続きます。
30+は、30ヶ月経過しイベント発生なし(生存中)
30は、30ヶ月目にイベント発生(死亡)
52は、52ヶ月目にイベント発生(死亡)
25+は、25ヶ月経過しイベント発生なし(生存中)
というように、それぞれの生存期間に、イベント発生有無のタグをつけて返してくれているんですね。
生存分析モデル (survival model) の構築
# 生存分析モデル (survival model) の構築
km_fit <- survfit(surv_obj ~ drug_A, data = X)このコマンドは Kaplan-Meier 生存曲線 (Kaplan-Meier Survival Curve) を作成するための 生存分析モデル (survival model) を構築するものです。
survfit() は Kaplan-Meier 生存曲線 や Cox回帰モデル で生存確率を推定するための関数で、survival パッケージ (library(survival)) に含まれています。
survfit()に先程構築したSurv()オブジェクトを指定することで、生存確率を推定できます。
surv_obj → 生存時間とイベント情報をまとめたオブジェクト (Surv() で作成)
drug_A → 解析するグループ分けの変数(この場合は、drug_Aありなし)
data = X → データフレーム”X”を使用
つまり、このスクリプトによって
「drug_A の2群(0 = No Drug, 1 = Drug A)で Kaplan-Meier 生存曲線を比較する」
ことができます!
print(km_fit)で中身をみてみましょう。
> print(km_fit)
Call: survfit(formula = surv_obj ~ drug_A, data = X)
n events median 0.95LCL 0.95UCL
drug_A=0 57 31 44 37 53
drug_A=1 43 23 40 26 NAここからわかることは、
drug_Aなしは57名、イベント発生(死亡)は31名、生存期間中央値(median)は44ヶ月(95% CI:37-53)。
drug_Aありは43名、イベント発生(死亡)は23名、生存期間中央値(median)は40ヶ月(95% CI:26-NA)(NAは未到達)。
と、論文でもよく見る非常に大事な情報が満載であることがわかりますね!
Kaplan-Meier曲線を描こう!
# Kaplan-Meier曲線を描画
ggsurvplot(
km_fit,
data = X,
conf.int = TRUE, # 信頼区間を表示
pval = TRUE, # Log-rank検定のp値を表示
risk.table = TRUE, # リスクテーブルを表示
legend.labs = c("No Drug A", "Drug A"), # 凡例のラベル
legend.title = "Treatment", # 凡例のタイトル
xlab = "Time (months)", # X軸ラベル
ylab = "Survival Probability", # Y軸ラベル
palette = c("#E7B800", "#2E9FDF") # 色指定
)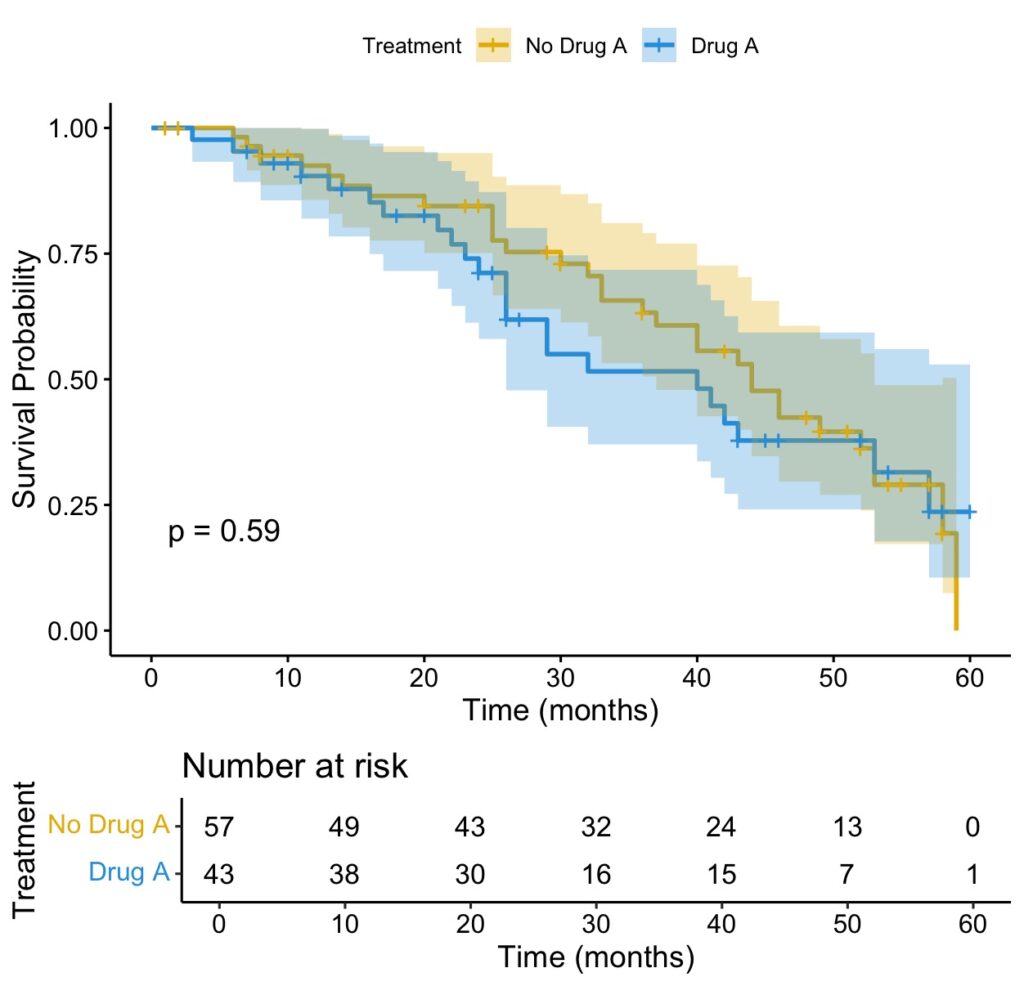
このようにキレイなグラフを描くことができました!
ggplot2を用いたグラフ作成は、様々なサイトで紹介されているので、参考にしてみてください。
ブログの末尾に紹介しておきますね。
COX比例ハザードモデル
cox_unweighted <- coxph(Surv(survival_month, survival) ~ drug_A + age + sex + BMI + Hb + PS, data = X)
summary(cox_unweighted) #結果の表示COX比例ハザードモデルの結果は、下記のように表示されます。
> cox_unweighted <- coxph(Surv(survival_month, survival) ~ drug_A + age + sex + BMI + Hb + PS, data = X)
> summary(cox_unweighted) #結果の表示
Call:
coxph(formula = Surv(survival_month, survival) ~ drug_A + age +
sex + BMI + Hb + PS, data = X)
n= 100, number of events= 54
coef exp(coef) se(coef) z Pr(>|z|)
drug_A[T.1] 0.090263 1.094462 0.281150 0.321 0.748
age 0.014022 1.014120 0.010763 1.303 0.193
sex -0.557361 0.572718 0.291667 -1.911 0.056 .
BMI 0.000719 1.000719 0.027830 0.026 0.979
Hb -0.040554 0.960257 0.062281 -0.651 0.515
PS -0.059053 0.942657 0.100499 -0.588 0.557
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
exp(coef) exp(-coef) lower .95 upper .95
drug_A[T.1] 1.0945 0.9137 0.6308 1.899
age 1.0141 0.9861 0.9930 1.036
sex 0.5727 1.7461 0.3234 1.014
BMI 1.0007 0.9993 0.9476 1.057
Hb 0.9603 1.0414 0.8499 1.085
PS 0.9427 1.0608 0.7741 1.148
Concordance= 0.59 (se = 0.042 )
Likelihood ratio test= 5.85 on 6 df, p=0.4
Wald test = 5.74 on 6 df, p=0.5
Score (logrank) test = 5.84 on 6 df, p=0.4
exp(coef)はHR、つまりハザード比のことです。
exp(coef) = 1.0855 → HR = 1.085
つまり、drug_A = 1 の患者は drug_A = 0 に比べて死亡リスクが 1.085 倍ということになります。
p値は、z Pr(>|z|)を参照します。p値 = 0.78です。
drug_A の影響は 統計的に有意ではないことになります。
信頼区間は lower .95とupper .95を参照します。信頼区間は0.6101 – 1.931となります。
信頼区間に1.0 を含むため、drug_Aの影響があるとは言えないことになります。
Wald testはWard検定とよばれるものです。Cox比例ハザードモデルの係数の有意性の評価に用いられます。
さいごに
# スクリプト全景
library(tibble)
library(survival)
library(survminer)
set.seed(123)
n <- 100
X <- tibble(
drug_A = sample(0:1, n, replace = TRUE),
survival = sample(0:1, n, replace = TRUE),
survival_month = sample(1:60, n, replace = TRUE),
age = sample(40:90, n, replace = TRUE),
sex = sample(0:1, n, replace = TRUE),
BMI = round(runif(n, 18, 35), 1),
Hb = round(runif(n, 8, 16), 1),
PS = sample(0:4, n, replace = TRUE)
)
X
write.csv(X, "synthetic_patient_data.csv", row.names = FALSE)
surv_obj <- Surv(time = X$survival_month, event = X$survival)
km_fit <- survfit(surv_obj ~ drug_A, data = X)
ggsurvplot(
km_fit,
data = X,
conf.int = TRUE,
pval = TRUE,
risk.table = TRUE,
legend.labs = c("Male", "Female"),
legend.title = "Sex",
xlab = "Time (months)",
ylab = "Survival Probability",
palette = c("#E7B800", "#2E9FDF")
)
cox_unweighted <- coxph(Surv(survival_month, survival) ~ drug_A + age + sex + BMI + Hb + PS, data = X)
summary(cox_unweighted)

コメント